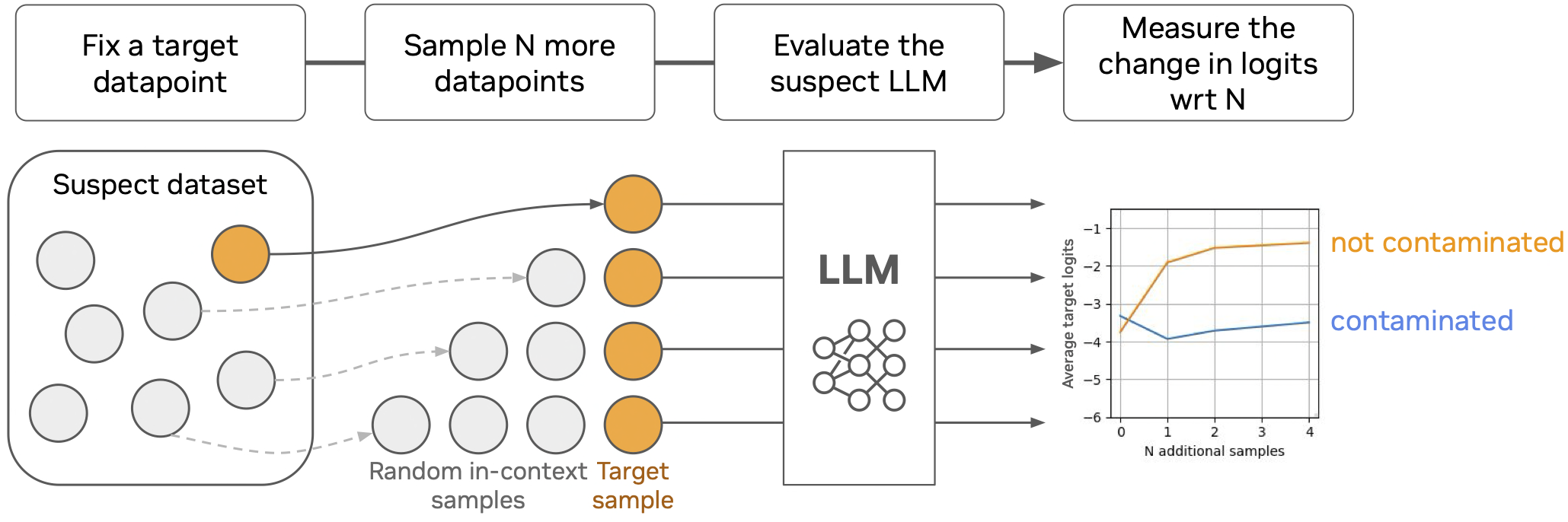
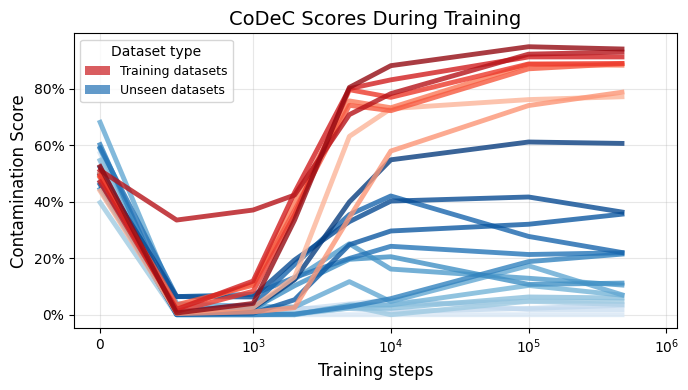
Early Detection During Training
Tracking CoDeC scores across OLMo 7B training checkpoints, we find that scores reach their final values after just 2% of training (10k out of 477k steps). This enables early intervention during model development, before significant training resources are spent.
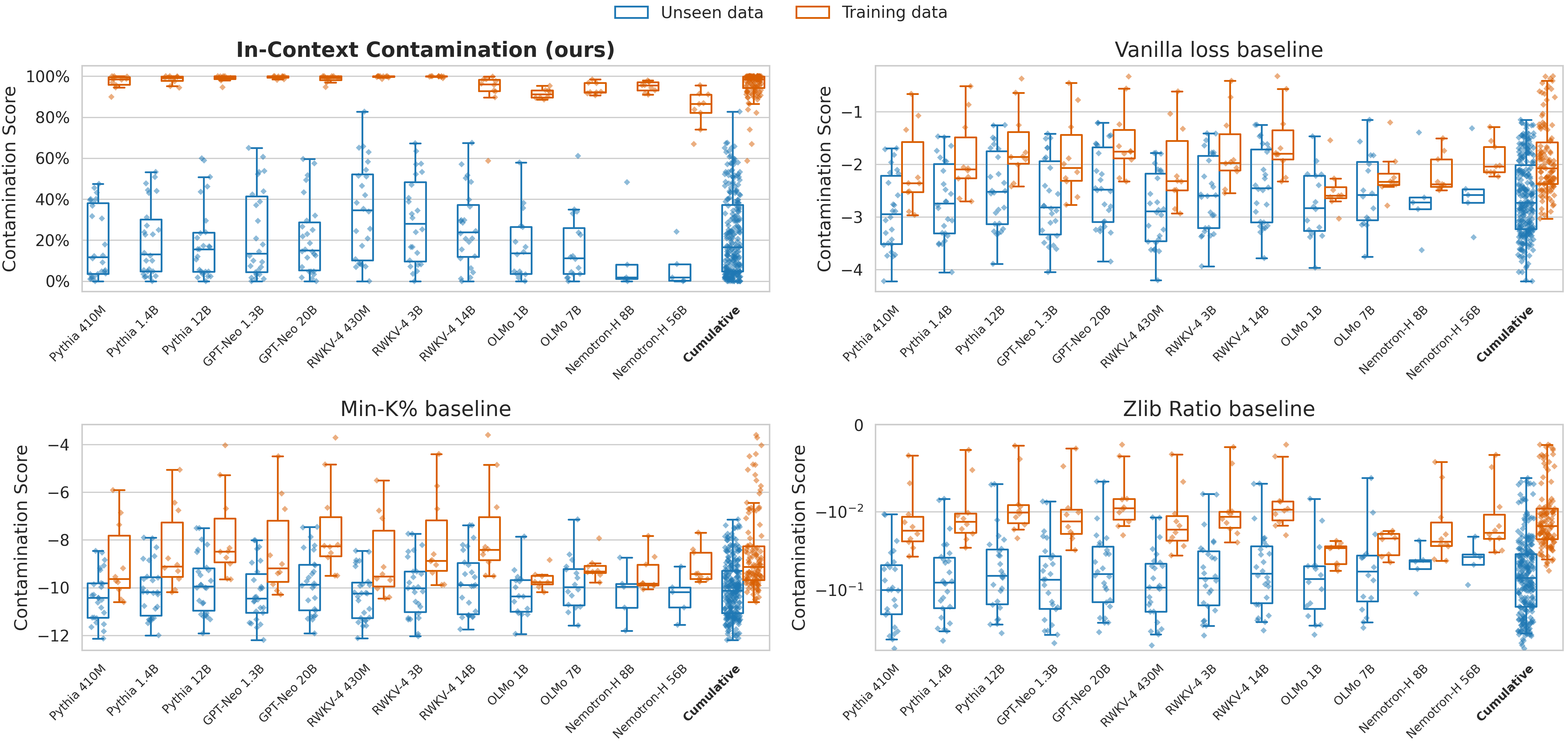
CoDeC Scores Depend on Data, Not Model Specifics
CoDeC scores are primarily determined by the relationship between the training corpus and the target benchmark. For models trained on the same data (e.g., the Pile), scores for each dataset are narrowly distributed. This stability enables meaningful cross-model comparisons: consistent scores reflect a dataset-level property, while deviations signal model-specific memorization.

CoDeC scores for models trained on the Pile. The last 10 datasets are parts of the training data. Scores usually cluster around a dataset-specific mean.
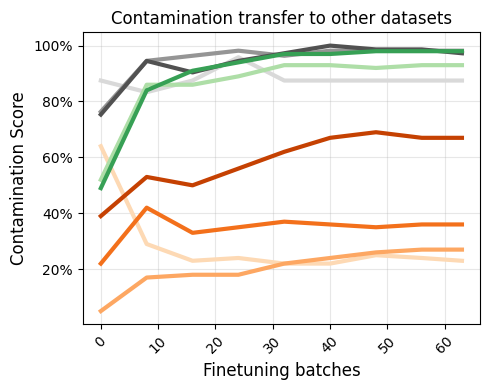
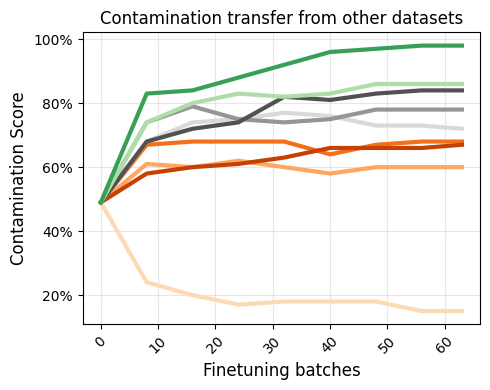
Contamination Transfer
CoDeC detects indirect contamination from rephrased, augmented, or otherwise related data. The model becomes contaminated with MMLU even when trained on questions that were unseen, highly cropped, rephrased, noised, or highly related. This cannot be captured by simple n-gram overlap checks.
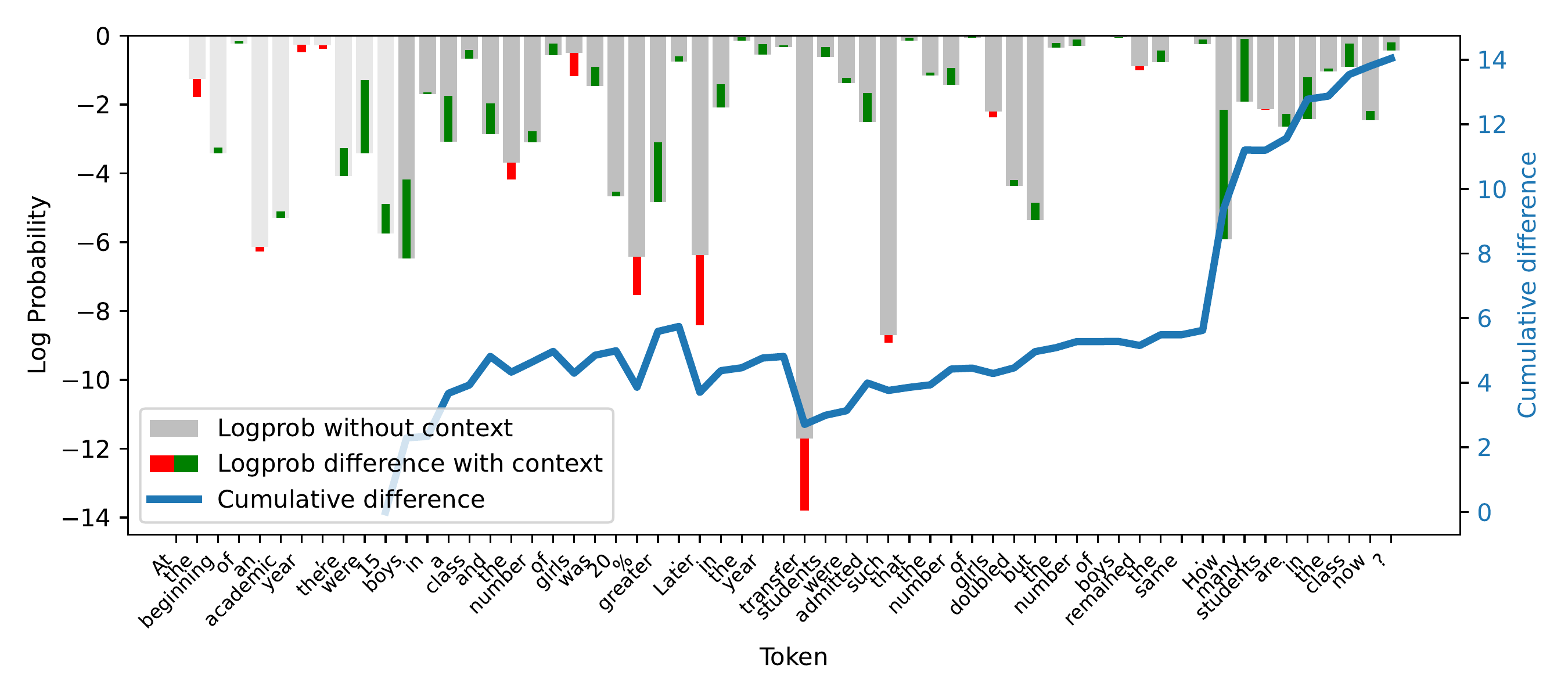
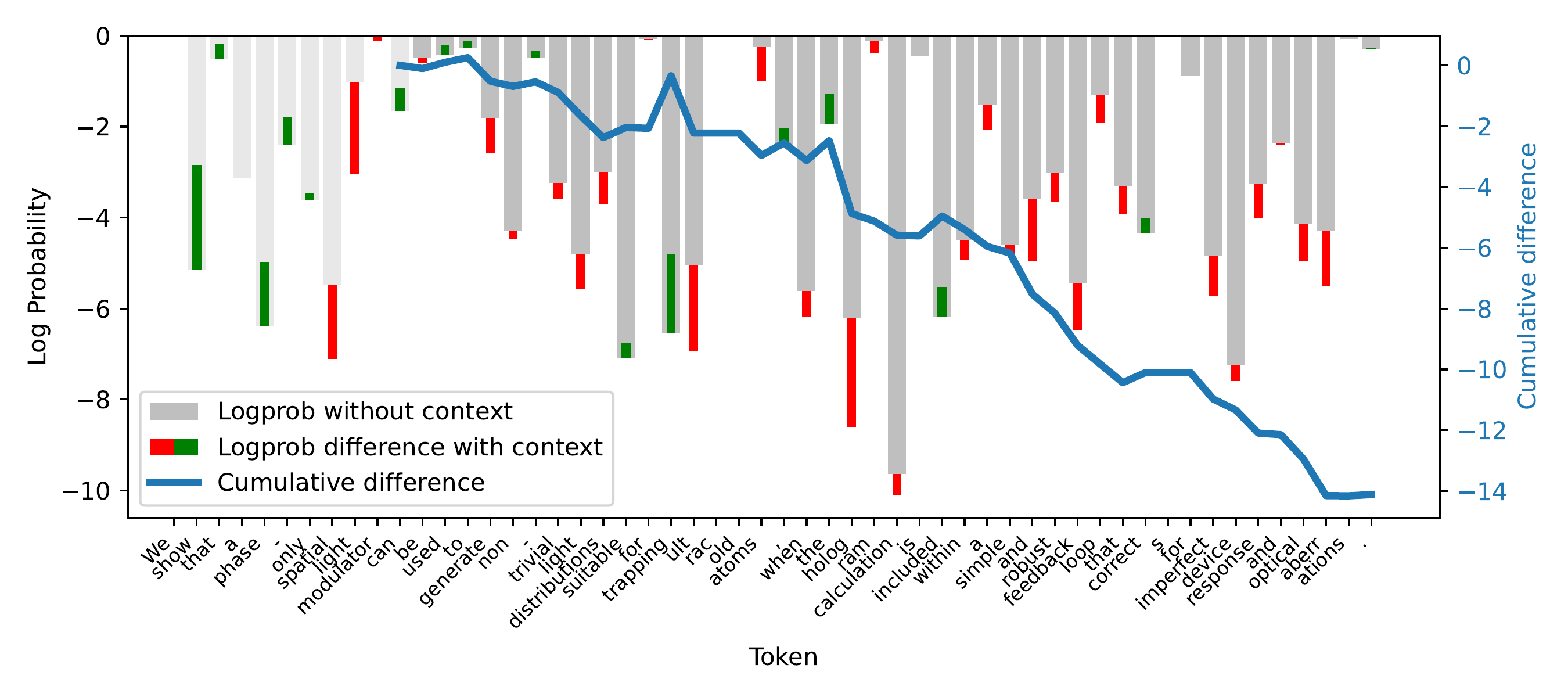
In-Context Learning Mirrors Finetuning
Adding in-context samples and finetuning with a moderate learning rate produce nearly identical confidence curves. For unseen data, both increase confidence with dimnishing gains; for training data, both decrease it in the first step, but then slowly increase it again. This pattern is due to the high variability of local minima in the loss landscape. This explains why CoDeC works: it measures the same underlying phenomenon as actual training—the remaining learning capacity for the target distribution—but at negligible computational cost.
Left: confidence change as in-context samples are added. Right: confidence change during finetuning at various learning rates. The curves are strikingly similar.
Sample Efficiency
CoDeC yields stable estimates with as few as 100 samples, and variance drops below 1% with 1,000 samples. The method requires only two forward passes per sample, is model-agnostic, dataset-agnostic, and parameter-free—no thresholds to tune, no reference models needed.

Verifying Decontamination Claims
CoDeC can independently verify decontamination procedures described in technical reports. For example, Qwen 2.5 scores 100% contamination on GSM8K's training set but only 27% on the test set. According to its technical report, training set of GSM8K was deliberately included in training, but with questions overlapping the test set removed. CoDeC confirms both the deliberate inclusion and the successful decontamination—without requiring access to the training data or any prior knowledge of the data curation process.